📱 中国 | AI Nation Rising

2024년 중국 인공지능 산업 시장 분석
1.0 서론: 중국 AI 산업의 현주소와 보고서의 목적
중국 인공지능(AI) 산업은 글로벌 기술 패권 경쟁의 핵심 영역으로 부상했으며, 특히 대형 모델(Large Model)의 등장으로 촉발된 기술 전환기에 중대한 기로에 서 있습니다. 급변하는 기술 환경과 복잡한 거시 경제 상황 속에서 중국 AI 시장은 새로운 도전과 기회에 동시에 직면하고 있습니다.
본 보고서는 투자자, 정책 입안자, 그리고 업계 전문가들이 중국 AI 시장의 다각적인 환경을 심도 있게 이해하는 데 필요한 통찰력을 제공하는 것을 목표로 합니다. 이를 위해 거시 및 사회 환경, 핵심 기술 동향, 주요 응용 분야, 상업화 모델, 그리고 대표 기업들의 전략을 체계적으로 분석하여 향후 시장의 발전 방향을 전망하고자 합니다.
2.0 거시 및 사회 환경 분석: 기회와 도전 과제
인공지능 산업의 성장은 기술 자체의 발전뿐만 아니라, 이를 둘러싼 외부 거시 환경에 의해 크게 좌우됩니다. 경제적 상황과 사회적 인식은 AI 기술의 채택 속도와 방향성에 직접적인 영향을 미치므로, 이에 대한 면밀한 분석은 시장을 이해하는 전제 조건입니다.
2.1 경제적 배경: 이중적 영향
최근 중국의 거시 경제는 코로나19 팬데믹의 충격으로 2020년 GDP 성장률이 2.2%까지 둔화된 이후, 회복세에도 불구하고 이전보다 낮은 성장 추세를 보이고 있습니다. 또한, 최근 소비자물가지수(CPI)의 지속적인 하락세는 상당한 디플레이션 압력을 시사하며, 이는 중국 AI 산업에 다음과 같은 이중적인 영향을 미칩니다.
- 도전 과제: 경제 침체는 기업의 투자 심리를 위축시켜 AI 분야의 투자 감소와 자금 조달의 어려움을 야기합니다. 또한, 전반적인 시장 수요 위축은 AI 솔루션 도입을 지연시키는 핵심적인 제약 요인으로 작용합니다.
- 기회 요인: 반면, AI 기술은 생산 효율성 향상과 비즈니스 모델 혁신을 통해 경제 성장을 촉진하는 핵심 동력으로 작용합니다. 어려운 경제 상황을 타개하기 위한 수단으로서 AI의 가치가 부각되고 있으며, 국가 차원의 강력한 정책 지원은 산업의 고품질 성장을 견인하여 소비와 투자를 활성화하고 경제 회복에 기여하는 핵심 동력입니다.
이러한 이중성은 초기 단계의 AI 스타트업이 자금 조달에 어려움을 겪는 반면, 강력한 자본을 보유한 기존 기술 대기업들은 AI를 활용하여 시장 통합과 효율성 증대를 가속화할 수 있는 독보적인 위치에 있음을 시사합니다. 이는 잠재적으로 시장 선도 기업과 신규 진입자 간의 격차를 더욱 확대시킬 수 있습니다.
2.2 사회적 인식: 기대와 불안의 공존
중국 대중의 AI에 대한 인식은 기술 이해도가 높아짐에 따라 더욱 뚜렷하고 양극화되는 양상을 보입니다. AI에 대해 '매우 잘 안다'고 응답한 집단에서는 긍정적 감정(기대, 놀라움)이 80.8%에 달하는 반면, '조금 안다'고 답한 집단에서는 71.1%로 나타나, 기술에 대한 친숙도가 긍정적 기대를 높이는 것으로 분석됩니다. 그러나 동시에, 부정적 감정(불안, 당혹감) 역시 이해도가 높은 집단에서 17.8%로, 낮은 집단(7.0%)보다 두 배 이상 높게 나타났습니다. 가장 주목할 만한 변화는 기술 이해도가 높아질수록 '중립적(평온, 막막함)' 또는 '무관심'과 같은 미온적인 태도가 거의 사라진다는 점입니다. 이는 AI에 대한 이해가 깊어질수록 단순히 긍정적, 부정적 감정이 모두 증가하는 것을 넘어, 기술에 대한 대중의 의견이 더욱 강력하고 명확하게 양분되고 있음을 의미합니다.
이러한 거시적 환경은 AI 기술 자체의 발전 방향에도 영향을 미칩니다. 다음 장에서는 현재 중국 AI 산업을 주도하고 있는 핵심 기술의 발전 동향을 심층적으로 분석하겠습니다.
3.0 핵심 기술 발전 동향: 대형 모델 시대로의 전환
과거 특정 작업에 최적화된 소형 모델 중심의 AI 패러다임은 이제 범용성과 확장성을 갖춘 대형 언어 모델(LLM) 중심으로 전략적으로 전환되었습니다. 이는 AI 기술의 발전 경로와 상업적 잠재력을 근본적으로 바꾸어 놓은 중대한 변화입니다.
3.1 기술 발전의 주요 마일스톤
핵심 AI 아키텍처는 지난 수십 년간 뚜렷한 발전 단계를 거쳐왔습니다.
- 기반 모델: 1980년대에 등장한 CNN(Convolutional Neural Network)은 이미지 인식 분야에서, 이후 등장한 RNN(Recurrent Neural Network)은 자연어 처리와 같은 시계열 데이터 처리에서 핵심적인 역할을 수행하며 '소형 모델' 시대를 열었습니다.
- 생성 모델의 부상: 2014년 GAN(Generative Adversarial Network)과 이후의 Diffusion 모델은 고품질의 이미지, 텍스트, 음성 데이터를 생성하는 능력을 선보이며 AI의 창의적 잠재력을 입증했습니다.
- 패러다임 전환: 2017년 구글이 발표한 Transformer 아키텍처는 AI 기술의 결정적인 전환점이 되었습니다. 이 아키텍처를 기반으로 2018년 BERT, GPT-1과 같은 모델들이 등장했으며, 2022년 말 ChatGPT의 출시는 본격적인 대형 모델 시대를 알리는 신호탄이 되었습니다.
3.2 대형 모델(LLM)의 최신 동향
대형 모델 분야는 현재 세 가지 핵심 트렌드를 중심으로 빠르게 발전하고 있습니다.
- 스케일링 법칙(Scaling Law)의 지속: 일부 선두 기업들은 여전히 파라미터, 데이터, 컴퓨팅 자원의 규모를 확장하는 '규모의 힘'을 통해 모델의 범용 성능을 극대화하는 전략을 추구하고 있습니다. 이는 모델의 정확도를 높이고 '환각(Hallucination)' 현상을 줄이는 데 기여합니다.
- 다중모드(Multi-modality)로의 확장: 최신 모델들은 텍스트의 한계를 넘어 음성, 이미지를 통합적으로 처리하는 방향으로 진화하고 있습니다. OpenAI의 GPT-4o가 대표적인 예로, 여러 모달리티를 동시에 이해하고 상호작용함으로써 보다 인간과 유사한 소통을 가능하게 합니다.
- 추론 능력 강화: 단순 정보 검색을 넘어 복잡한 문제를 논리적으로 해결하는 능력이 중요해지고 있습니다. '사고 사슬(CoT, Chain of Thoughts)'과 같은 기술은 모델이 문제 해결 과정을 단계적으로 생각하도록 유도하여 추론의 정확성을 높이는 핵심 연구 분야입니다.
3.3 대형 모델의 상용화 경로
사전 훈련된 대형 모델을 실제 비즈니스에 적용하기 위해서는 특정 목적에 맞게 모델을 최적화하는 과정이 필수적입니다. 주요 기술 경로는 다음과 같습니다.
- 후훈련 / 증분 사전훈련 (Post-training / Incremental Pre-training): 특정 분야의 데이터를 추가로 학습시켜 모델의 기초 능력을 강화하는 기법입니다.
- 미세조정 (Fine-tuning): 소량의 특정 데이터셋을 사용하여 모델을 특정 작업에 맞게 조정하는 방식으로, SFT(Supervised Fine-tuning), RLHF(Reinforcement Learning from Human Feedback) 등이 포함됩니다.
- 증류 (Distillation): 거대한 '교사' 모델을 사용하여 작고 효율적인 '학생' 모델을 훈련시켜, 적은 리소스로도 높은 성능을 달성하는 모델 압축 기술입니다.
- 검색 증강 생성 (RAG, Retrieval-Augmented Generation): 모델의 내부 지식에만 의존하지 않고, 외부 데이터베이스나 지식 베이스를 실시간으로 검색하여 답변의 정확성과 신뢰도를 높이는 방식입니다.
특히 DeepSeek, 알리 Qwen(QwQ)과 같이 저비용으로 고성능을 구현한 오픈소스 모델의 등장은 기업들이 AI를 도입하는 기술적, 비용적 장벽을 크게 낮추며 상용화를 가속화하는 기폭제 역할을 하고 있습니다. 이러한 기술들은 다양한 산업 분야에서 구체적인 응용 프로그램으로 구현되고 있으며, 다음 장에서는 그 현황을 살펴보겠습니다.
4.0 주요 응용 분야 및 시장 동향 분석
AI 기술의 진정한 가치는 특정 응용 분야에서 비즈니스 문제를 해결하고 새로운 시장을 창출할 때 발현됩니다. 따라서 주요 응용 분야를 분석하는 것은 AI 기술의 시장성을 파악하는 데 매우 중요합니다.
4.1 AI 코딩 (AI Coding): 프로그래밍의 민주화
AI 코딩 도구는 단순한 코드 완성 보조 도구(Copilot)에서 점차 자율적으로 복잡한 개발 작업을 수행하는 Agent로 진화하고 있습니다. 이러한 발전은 전문 개발자의 생산성을 극대화하는 동시에, 비전문가도 소프트웨어 개발에 참여할 수 있는 길을 열어주고 있습니다.
| 분류 | 주요 특징 |
| 개발자용 AI 코딩 | 코드 완성, 디버깅 최적화, 코드 리팩토링 등 전문 개발자의 반복적인 작업을 자동화하여 생산성 향상에 초점을 맞춥니다. |
| 모두를 위한 AI 코딩 | 자연어 명령이나 그래픽 인터페이스를 통해 비전문가도 소프트웨어를 개발할 수 있도록 진입 장벽을 낮추는 것을 목표로 합니다. |
과거 전문가의 영역이었던 영상 편집이 사용자 친화적인 도구의 등장으로 대중화되었듯이, AI 코딩은 프로그래밍의 민주화를 촉진하고 있습니다. 특히 '모두를 위한 AI 코딩'의 궁극적인 목표는 '자연어 명령'에서 '소프트웨어 배포'까지의 전 과정을 자동화하는 것으로, 이는 소프트웨어 제품 생태계를 더욱 다양하고 개인화된 방향으로 근본적으로 변화시킬 것입니다.
4.2 AI 음성 (AI Voice): 상호작용의 혁신
음성 AI 기술은 음성 인식(ASR), 자연어 이해(LLM), 음성 합성(TTS) 모듈을 순차적으로 처리하는 전통적인 '계단식(Cascaded)' 아키텍처에서 음성 신호를 직접 처리하고 생성하는 '엔드투엔드(End-to-End)' 모델로 전환되고 있습니다.
| 아키텍처 | 장점 | 단점 |
| 계단식 (Cascaded) | 각 모듈의 제어가 용이하고 정확성이 높음 | 처리 단계가 많아 지연 시간이 김 |
| 엔드투엔드 (End-to-End) | 지연 시간이 짧고 자연스러운 상호작용 가능 | 제어 가능성과 정확성 확보에 어려움, 환각 문제 발생 가능 |
이러한 기술 발전을 기반으로 AI 음성 시장은 다음과 같은 주요 제품군으로 확장되고 있습니다.
- AI 대화형 제품: 스마트客服, 교육, 마케팅 등에서 활용
- AI 소셜 및 동반자 제품: 가상 캐릭터와의 음성 대화를 통한 정서적 교감 제공
- AI 음성 콘텐츠 생성 제품: 텍스트를 오디오북, 팟캐스트 등으로 변환 (예: ElevenLabs)
- AI 음악 생성 제품: 텍스트나 멜로디 프롬프트를 기반으로 독창적인 음악 생성 (예: Suno AI)
4.3 AI 비전 (Visual Modality): 성숙과 신흥의 공존
AI 비전 분야의 투자는 크게 두 갈래로 집중되고 있습니다. 하나는 상업화가 성숙된 '머신 비전' 분야이며, 다른 하나는 폭발적인 성장 잠재력을 지닌 신흥 '생성형 AI' 분야입니다.
- 2024년 기준, 시각 생성형 AI 분야 기업의 70%는 2023년 이후 설립된 신생 기업으로, 시장의 높은 기대감을 반영합니다.
- 그러나 C라운드 이상의 성숙 단계 투자는 대부분 기술적 안정성과 명확한 수익 모델을 갖춘 머신 비전 분야에서 이루어지고 있어, 시장의 신중한 태도 또한 엿볼 수 있습니다.
기술적으로는 이미지/비디오를 생성하는 DiT(Diffusion Transformer) 모델과 이미지/비디오를 이해하고 분석하는 MLLM(Multi-modal Large Language Model)이 양대 축을 이루고 있습니다. 현재 두 기술 경로는 분리되어 있지만, 장기적으로는 생성과 이해 능력이 융합된 통합 모델로 발전하여 더 넓은 응용 가치를 창출할 것으로 전망됩니다. 이러한 다양한 응용 프로그램들이 지속 가능한 비즈니스로 성장하기 위해서는 효과적인 수익화 전략이 필수적입니다. 다음 장에서는 AI 기업들의 상업화 모델을 분석하겠습니다.
5.0 상업화 모델 및 해외 진출 전략
혁신적인 AI 기술을 개발하는 것만큼이나 중요한 과제는 이를 지속 가능한 수익으로 연결하고 시장을 확장하는 것입니다. 중국 AI 기업들은 다양한 상업화 모델을 모색하는 동시에, 성장의 한계를 극복하기 위해 해외 시장으로 눈을 돌리고 있습니다.
5.1 핵심 상업화 모델 분석
현재 중국 AI 산업에서 통용되는 주요 비즈니스 모델은 다음과 같습니다.
| 모델 유형 | 설명 | 주요 대상 |
| 프로젝트 기반 | 특정 고객의 요구에 맞춰 소프트웨어, 하드웨어, 서비스를 통합한 맞춤형 솔루션을 제공하고 비용을 청구하는 모델입니다. | 정부(to G), 대기업(to B) |
| MaaS (Model as a Service) | 클라우드 플랫폼을 통해 AI 모델의 API를 제공하고 사용량(호출 횟수, 토큰 수 등)에 따라 과금하는 모델입니다. | 개발자, 기업(to B) |
| SaaS (구독형) | AI 기능이 탑재된 소프트웨어를 월간 또는 연간 구독 형태로 제공하는 모델로, 일반 사용자에게 가장 익숙한 방식입니다. | 일반 소비자(to C), 중소기업(to B) |
이와 더불어, 성과 기반 과금(Pay-for-performance)이나 특정 작업을 자율적으로 수행하는 AI Agent 서비스와 같이 고객이 창출한 가치에 직접 연동되는 혁신적인 모델들이 새로운 수익 창출 방안으로 모색되고 있습니다. 이는 단순 기능 제공을 넘어 실질적인 비즈니스 성과를 보장해야 하므로 더 높은 수준의 기술력과 신뢰를 요구합니다.
5.2 해외 시장 진출 전략 및 과제
중국 AI 기업들은 내수 시장의 치열한 경쟁을 넘어 새로운 성장 동력을 확보하기 위해 적극적으로 해외 시장에 진출하고 있습니다.
- 주요 동기:
- 중국보다 넓은 글로벌 시장 공간 확보
- 상대적으로 높은 유료 전환율과 성숙한 사용자 지불 습관
- 일부 신흥 시장에서의 선점 효과 기대
- AI 기반 번역 기술 발달로 언어 및 문화 장벽 감소
- 전략적 고려사항:
- 지역 선택: 구매력이 높은 미국, 영국 등 영어권 시장, 성장 잠재력이 큰 동남아, 중동 등 신흥 시장, 또는 특정 문화권에 특화된 일본 시장 등을 타겟으로 합니다.
- 주요 도전 과제:
- 현지화: 각기 다른 문화, 사용자 습관, 인종적 다양성을 고려한 제품 및 마케팅 전략 수립
- 글로벌 경쟁: 구글, OpenAI 등 강력한 글로벌 기업과의 경쟁
- 데이터 규제: 데이터의 국경 간 전송, 사용자 개인정보 보호 등 각국의 엄격한 규제 준수
이러한 전략을 실행하며 시장을 개척하고 있는 대표적인 기업들의 사례를 다음 장에서 분석하겠습니다.
6.0 주요 기업 사례 연구: 경쟁 구도 심층 분석
중국 AI 시장의 경쟁 생태계를 이해하기 위해서는 주요 플레이어들의 전략을 분석하는 것이 필수적입니다. 각 기업은 자신들의 강점을 기반으로 차별화된 접근 방식을 통해 시장 지배력을 확대하고 있습니다.
6.1 바이트댄스 (ByteDance): 통합 생태계 구축
바이트댄스는 AI 기술을 자사 서비스 전반에 깊숙이 통합하는 포괄적인 전략을 구사하고 있습니다. 이들의 전략은 다음과 같은 4계층 제품 매트릭스로 명확하게 정의됩니다.
- 기초 대형 모델 (Base Large Model): 자체 개발한 豆包(Doubao) 시리즈를 중심으로 다양한 유형의 모델을 제공하여 기술 기반을 다집니다.
- 대형 모델 개발 플랫폼 (Large Model Development Platform): 火山方舟(Volcano Engine)를 통해 개발자들이 모델을 쉽게 활용하고 미세조정할 수 있는 환경을 제공합니다.
- 스마트 에이전트 개발 플랫폼 (Agent Development Platform): 코딩 지식이 없는 사용자도 AI 앱을 만들 수 있는 扣子(Coze) 플랫폼을 통해 개발자 생태계를 폭넓게 확장합니다.
- 대형 모델 응용 프로그램 계층 (Large Model Application Layer): Doubao AI 어시스턴트를 필두로 글쓰기, 이미지 생성 등 다양한 기능을 제공하여 일반 사용자와 기업 고객의 요구를 모두 충족시킵니다.
이처럼 바이트댄스는 기초 모델부터 최종 애플리케이션까지 수직적으로 통합된 생태계를 구축하여 시너지를 극대화하고 있습니다.
6.2 알리바바 (Alibaba): 기존 서비스와의 AI 융합
알리바바는 자사가 보유한 방대한 B2B 서비스에 AI를 접목하여 기존 제품의 가치를 높이는 전략에 집중하고 있습니다. 대표적인 사례는 알리메일(阿里邮箱)입니다.
AI는 스팸 방지, 데이터 보안 등 전통적인 이메일 기능을 강화하는 것을 넘어, 이메일을 비즈니스 자동화의 출발점으로 전환시키는 전략적 역할을 수행합니다. 알리메일은 통의천문(Tongyi Qianwen), DeepSeek 등 다양한 대형 모델과 연동하여 이메일에 담긴 비정형 데이터를 분석하고, 이를 구조화된 **메타데이터(metadata)**로 변환합니다. 이렇게 변환된 데이터는 기업의 인사, 재무, 공급망 등 핵심 업무 시스템과 연결되는 RPA 워크플로우를 자동으로 실행하는 트리거로 작용합니다. 즉, 이메일은 단순한 소통 도구에서 자동화된 비즈니스 프로세스의 핵심 데이터 소스로 진화하고 있습니다.
6.3 딥시크 (DeepSeek): 오픈소스 기반의 기술 혁신
딥시크는 '오픈소스' 철학을 핵심 경쟁력으로 삼아 업계에 강력한 영향력을 미치고 있는 신흥 강자입니다. 이들의 혁신은 세 가지 축으로 요약됩니다.
- 엔지니어링 최적화: DeepSeek V3 모델을 통해 MoE(Mixture of Experts) 아키텍처를 최적화하여, 제한된 자원으로도 최고 수준의 성능을 내는 저비용·고효율 훈련 및 추론 기술을 실현했습니다.
- 알고리즘 패러다임 혁신: DeepSeek R1 모델은 순수 강화학습(RL) 경로의 가능성을 입증했다는 점에서 혁신적입니다. 이는 전통적인 지도 미세조정(SFT) 단계를 건너뛰고 모델이 스스로 추론 능력을 향상시키는 새로운 훈련 패러다임을 제시한 것으로, 비용이 많이 드는 인간의 데이터 라벨링 의존도를 획기적으로 줄일 수 있는 잠재력을 보여줍니다.
- 개방형 생태계 전략: 모델의 가중치, 기술 논문, 훈련 코드 일부를 공개함으로써 전 세계 개발자 커뮤니티의 참여를 유도합니다. 커뮤니티의 피드백과 기여를 통해 모델을 빠르게 개선하는 선순환 구조를 구축하여 강력한 기술 생태계를 형성하고 있습니다.
현재 시장을 주도하는 기업들의 전략을 넘어, 이제 AI 기술이 앞으로 나아갈 방향과 그에 따른 과제를 전망해 보겠습니다.
7.0 미래 전망 및 주요 과제
중국 AI 산업은 대형 모델의 고도화를 넘어, 디지털 지능을 현실 세계와 연결하고 그 과정에서 발생하는 새로운 도전 과제에 대응해야 하는 다음 단계로 진입하고 있습니다.
7.1 AI 에이전트와 물리적 AI
**AI 에이전트(AI Agent)**는 대형 모델이 가진 강력한 '두뇌'(추론 능력)와 실제 응용 프로그램(도구) 사이의 간극을 메우는 핵심 기술입니다. 사용자의 복잡한 목표를 이해하고, 스스로 계획을 세우며, 필요한 도구를 자율적으로 사용하여 과업을 완수하는 '디지털 노동력'으로 부상하고 있습니다.
더 나아가, AI 발전의 다음 격전지는 디지털 세계를 넘어 물리적 세계와 상호작용하는 물리적 AI(Physical AI), 즉 '구체화된 지능(Embodied Intelligence)'이 될 것입니다. 이는 로보틱스 기술과 AI가 결합하여 공장 자동화, 물류, 노인 돌봄, 가사 노동 등 다양한 현실 세계의 문제를 해결하는 것을 목표로 합니다. 이 분야는 하드웨어와 소프트웨어의 긴밀한 통합, 실시간 반응성 확보, 그리고 윤리적 문제 해결 등 복합적인 과제를 안고 있습니다.
7.2 AI 안전 및 거버넌스
AI 기술이 사회 전반에 확산되면서 그에 따른 안전과 거버넌스 문제 또한 중요해지고 있습니다. 위험은 크게 기술 자체의 내재적 위험과 기술이 응용되면서 발생하는 사회적 위험으로 나눌 수 있습니다.
| 위험 유형 | 세부 내용 |
| 내재적 보안 (Endogenous Security) |
데이터 프라이버시 침해, 모델의 판단 근거를 알기 어려운 '블랙박스' 문제(설명 가능성 부족), 훈련 데이터의 편향으로 인한 알고리즘 편견, 악의적인 데이터로 모델을 오염시키는 '모델 투독(Model Poisoning)' 등 기술 자체의 위험을 포함합니다. |
| 응용 보안 (Application Security) |
AI를 악용한 허위 정보(딥페이크 등)의 대량 확산, 개인화 추천으로 인한 '정보 고치(정보茧房)' 심화, 사이버 공격 등 불법 활동에의 악용, AI의 결정으로 인한 사고 발생 시 책임 소재의 불분명성, 인간의 감성적 의존과 관련된 윤리 문제 등을 포함합니다. |
이러한 복합적인 위험에 효과적으로 대응하기 위해서는 단편적인 규제를 넘어, 기술 개발, 법률 제정, 사회적 윤리 규범, 그리고 국제적 협력을 아우르는 다각적이고 선제적인 거버넌스 프레임워크 구축이 시급합니다.
8.0 결론
2024년 중국 인공지능 산업은 어려운 거시 경제 환경 속에서도 강력한 회복탄력성을 보이며 질적 성장을 이어가고 있습니다. 본 보고서의 핵심 분석 내용은 다음과 같이 요약할 수 있습니다.
- 기술 패러다임의 전환: 산업의 중심은 대형 모델로 완전히 이동했으며, 스케일링, 다중모드, 추론 능력 강화가 핵심 기술 트렌드로 자리 잡았습니다.
- 상업화 및 생태계 구축: 주요 기업들은 단순히 우수한 모델을 개발하는 것을 넘어, 오픈소스 전략, 기존 서비스와의 융합, 수직적 생태계 구축 등 차별화된 전략을 통해 시장 지배력을 강화하고 있습니다.
- 미래 방향성: AI 기술은 AI 에이전트를 통해 자율성을 확보하고, 물리적 AI를 통해 현실 세계로 확장될 것입니다. 이는 새로운 기회를 창출하는 동시에 복잡한 기술적, 윤리적 과제를 제기합니다.
- 거버넌스의 시급성: 기술의 영향력이 커질수록 AI 안전과 거버넌스의 중요성은 더욱 부각될 것입니다. 신뢰할 수 있는 AI 생태계를 구축하기 위한 다각적인 노력이 필수적입니다.
결론적으로, 중국 AI 산업은 단기적인 경제적 도전에도 불구하고, 기술 혁신과 상업화 노력을 통해 장기적인 성장 동력을 확보해 나가고 있습니다. 투자자와 업계 전문가들은 개별 기술의 우수성뿐만 아니라, 각 기업이 구축하는 생태계의 경쟁력과 미래 트렌드에 대한 대응 능력을 종합적으로 평가하며 시장 기회를 모색해야 합니다. 따라서 향후 몇 년간의 핵심적인 전략적 차별점은 강력한 모델에 대한 접근성이 아닌(이는 점차 상품화되고 있으므로), 극복하기 어려운 사용자 락인(lock-in) 효과를 창출하는 강력한 데이터 플라이휠과 통합된 애플리케이션 생태계를 구축하는 능력이 될 것입니다.

중국 AI 산업 투자 제안서: 시각적 생성 AI의 부상과 투자 기회 분석
1. 서론: 기회와 도전이 공존하는 중국 AI 시장
중국이 GDP 성장률 둔화와 디플레이션 압력으로 정의되는 거시 경제적 난관을 헤쳐나가는 지금, 기술을 통한 혁신의 필요성은 그 어느 때보다 절실해졌습니다. 이러한 환경 속에서 인공지능(AI)은 단순한 성장 산업을 넘어, 생산성과 경제 회복력을 견인하는 핵심 동력으로 부상하며 독보적이고 강력한 투자 테제를 형성하고 있습니다.
본 투자 제안서는 이러한 복합적인 환경 속에서 중국 AI 시장의 유망 투자 분야를 심층적으로 분석합니다. 특히, 기술 패러다임 전환의 중심에 있는 시각적 생성 AI(Visual Generative AI) 분야의 폭발적인 성장 가능성에 주목하고, 관련 기업 생태계와 잠재적 리스크를 종합적으로 평가하여 투자자를 위한 균형 잡힌 관점을 제시하고자 합니다.
이를 통해, 우리는 기회와 도전이 공존하는 현시점에서 성공적인 투자 전략을 수립하는 데 필수적인 통찰력을 제공할 것입니다. 이제 중국 AI 시장을 둘러싼 구체적인 환경 분석을 통해 그 가능성을 탐색해 보겠습니다.
2. 진화하는 중국 AI 시장 환경 분석
성공적인 투자는 시장의 거시적 맥락과 기술의 핵심 동력을 정확히 이해하는 데서 출발합니다. 중국 AI 산업은 현재 저성장 경제라는 도전 과제와 대규모 모델이라는 기술적 변혁을 동시에 겪고 있습니다. 이 두 가지 요소를 면밀히 분석하는 것은 유망 투자처를 발굴하기 위한 필수적인 과정입니다.
2.1. 거시 경제 환경: 저성장 속 기회 탐색
최근 중국의 GDP 성장률은 과거 대비 둔화되었으며, CPI(소비자물가지수)는 하락 추세를 보이며 경제적 어려움이 가중되고 있습니다. 이러한 거시 경제 환경은 AI 산업에 양면적인 영향을 미치고 있습니다.
- 부정적 영향: 경기 침체는 기업의 투자 심리를 위축시키고 자금 조달 환경을 악화시켜 AI 산업의 단기적 성장을 저해하는 요인으로 작용합니다.
- 긍정적 영향: 반면, 기업들은 비용 절감과 생산 효율성 증대를 위해 AI 기술 도입을 가속화하고 있습니다. 이는 AI가 단순한 기술 트렌드를 넘어 기업의 생존과 성장을 위한 핵심 도구로 자리 잡고 있음을 의미합니다. 또한, 중국 정부의 강력한 정책적 지원은 AI 산업의 장기적인 성장 동력을 뒷받침하며 시장의 회복을 견인하고 있습니다.
2.2. 기술 패러다임의 전환: 대규모 모델과 멀티모달의 부상
AI 기술 아키텍처의 도약은 점진적 개선이 아닌 근본적인 전환이었습니다. CNN/RNN에서 Transformer 아키텍처로의 전환은 대규모 언어 모델에 필수적인 스케일링 법칙(Scaling Law)을 가능하게 했고, 이는 시장을 재정의한 ChatGPT의 등장으로 정점에 달했습니다. 이 전환은 현재의 멀티모달 혁명을 위한 무대를 마련했으며, Transformer 아키텍처는 텍스트를 넘어 ViT(Vision Transformer), **DiT(Diffusion Transformer)**와 같은 시각 대규모 모델로 확장되었습니다. OpenAI의 GPT-4o와 같은 최신 멀티모달 모델은 텍스트, 시각, 청각 정보를 통합 처리하며 AI의 적용 범위를 비약적으로 확장시키고 새로운 애플리케이션의 등장을 촉진하고 있습니다.
이와 동시에, DeepSeek, Alibaba의 Qwen(QwQ) 시리즈와 같이 저비용 고성능을 자랑하는 오픈소스 모델의 등장은 AI 기술의 상업적 도입 문턱을 크게 낮추고 있습니다. 기업들은 이를 활용해 자체 데이터로 미세조정(Fine-tuning)하거나 검색 증강 생성(RAG) 기술을 접목하여 특정 비즈니스에 최적화된 AI 솔루션을 보다 쉽게 구축할 수 있게 되었습니다.
이러한 기술적 진화 속에서 특히 주목해야 할 분야는 인간의 가장 중요한 감각인 '시각'을 다루는 AI 기술입니다. 다음 장에서는 왜 시각적 생성 AI가 현시점에서 가장 매력적인 투자처인지를 집중적으로 분석하겠습니다.
3. 핵심 투자 테제: 시각적 생성 AI 분야의 폭발적 성장 잠재력
텍스트를 넘어 이미지, 영상, 3D 등 시각적 콘텐츠를 생성하고 이해하는 AI 기술은 중국 AI 시장에서 가장 역동적인 성장 잠재력을 가진 분야로 부상하고 있습니다. 이 분야는 아직 시장 형성 초기 단계에 있어 성장 여력이 매우 크며, 최근 투자 동향은 자본이 이 분야의 미래 가치를 높게 평가하고 있음을 명확히 보여주고 있습니다.
3.1. 투자 동향으로 본 시장 검증
2024년 중국의 시각 모달리티 AI 분야 투자는 전통적인 머신 비전에서 생성형 AI로 자본이 이동하는 뚜렷한 흐름을 보여줍니다.
| 투자 분야 | 2024년 투자 비중 | 주요 특징 |
| 생성 중심 AI (이미지/영상/3D) |
62.5% | - 2023년 이후 설립된 신생 기업이 70% 차지<br>- 투자의 76%가 Seed/Angel, Pre A-B+ 등 초기 단계에 집중 |
| 판별 중심 머신 비전 | 37.5% | - 상업적 성숙도가 높음<br>- 후기 라운드(D+ 이상) 투자는 이 분야에서만 발생 |
데이터는 시장의 명확한 양분화를 보여줍니다. 판별 중심 머신 비전이 성숙하고 현금 흐름이 안정적인 시장을 대표하는 반면, 신규 자본의 압도적인 흐름—그중 76%가 생성형 AI 스타트업의 Seed/Angel부터 Pre A-B+ 라운드에 집중—은 시장이 이 신생 분야의 폭발적인 미래 성장을 가격에 반영하고 있음을 나타냅니다. 벤처 투자자의 알파(Alpha)는 명백히 생성형 AI 분야에 있습니다. 현명한 투자자에게 이는 유망 기업의 지분을 유리한 초기 밸류에이션으로 확보할 수 있는 결정적인 기회의 창이 열렸음을 의미합니다.
3.2. 핵심 성장 동력: 기술의 융합과 발전
시각적 생성 AI의 성장은 두 가지 핵심 기술 경로의 발전과 융합에 의해 주도될 것입니다.
- 생성 모델 (DiT: Diffusion Transformer): Sora, Midjourney 등에서 활용되는 이 아키텍처는 노이즈로부터 고품질 이미지나 영상을 생성하는 데 탁월한 성능을 보입니다.
- 이해 모델 (MLLM: Multi-modal Large Language Model): GPT-4o와 같이 텍스트와 이미지를 동시에 이해하고 분석하여 사용자의 복잡한 질문에 답하는 능력을 갖추고 있습니다.
현재는 생성과 이해 기술이 별개의 경로로 발전하고 있지만, 장기적으로는 이 두 능력이 융합된 **‘통합적 인식-생성 모델(Unified Perception-Generation Model)’**의 등장이 시각적 AI의 최종 진화 방향이 될 것입니다. 예를 들어, "이 영상의 문제점을 분석하고, 해결책을 반영한 새로운 영상을 만들어줘"와 같은 복합적인 명령을 수행하는 AI는 이 기술 융합을 통해 실현될 수 있습니다. 이 융합을 주도하는 기업이 시장의 가치를 독점적으로 확보하게 될 것이므로, 이는 투자자들이 주목해야 할 궁극적인 기술 로드맵입니다.
이처럼 폭발적인 성장 잠재력이 확인된 시각적 생성 AI 시장을 어떤 기업들이 주도하고 있는지, 다음 장에서 구체적인 사례를 통해 분석해 보겠습니다.
4. 주목할 만한 기업 및 생태계 분석
성공적인 투자는 유망한 분야를 선택하는 것을 넘어, 강력한 실행력과 차별화된 전략을 갖춘 기업을 식별하는 데 달려있습니다. 본 섹션에서는 각기 다른 접근 방식으로 중국 AI 시장을 선도하는 세 기업의 사례를 통해 성공적인 AI 비즈니스 모델을 분석하고 투자 기회를 구체화하고자 합니다.
4.1. 풀스택(Full-Stack) 혁신가: 바이트댄스(ByteDance)
바이트댄스는 AI 기술 스택 전반에 걸친 수직 통합 생태계를 구축하며 시장을 공략하고 있습니다. 이들의 전략은 4개의 계층으로 구성됩니다.
- 기초 대규모 모델: 자체 개발한 '더우바오(Doubao)' 모델 시리즈가 핵심 동력을 제공합니다.
- 개발 플랫폼: '화산방주(Volcano Ark)'를 통해 개발자들이 모델을 쉽게 활용하고 미세조정할 수 있도록 지원합니다.
- 스마트 에이전트 개발 플랫폼: '코우즈(Coze)'를 통해 코딩 지식이 없는 사용자도 손쉽게 AI 챗봇과 애플리케이션을 만들 수 있도록 합니다.
- 대규모 모델 애플리케이션: 최종 사용자에게 글쓰기, 이미지 생성, 정보 검색 등 다양한 AI 서비스를 제공합니다.
이러한 수직 통합 전략은 기초 기술부터 최종 애플리케이션까지 유기적으로 연결하여 강력한 시너지를 창출하며, 다양한 사용자 요구를 효과적으로 충족시키고 있습니다.
- 핵심 투자자 시사점: 바이트댄스의 핵심은 수직 통합 생태계의 힘에 있습니다. 기초 모델부터 대중 시장 애플리케이션에 이르기까지 전체 스택을 통제함으로써, 순수 모델 제공 기업이 복제하기 어려운 강력한 데이터 플라이휠(flywheel)과 방어적 해자(moat)를 구축합니다.
4.2. 오픈소스 파괴자: 딥시크(DeepSeek)
딥시크는 최첨단 AI 모델을 과감하게 오픈소스로 공개하는 파괴적인 전략을 통해 기술 생태계를 주도하고 있습니다.
- 개방형 생태계 구축: DeepSeek V3, R1과 같은 고성능 모델을 오픈소스로 공개함으로써 전 세계 개발자 커뮤니티를 활성화하고, 이를 통해 기술적 피드백을 얻는 선순환 구조를 만들어 강력한 기술적 해자를 구축하고 있습니다.
- 이중적 기술 혁신: 딥시크의 경쟁력은 두 가지 핵심 혁신에서 나옵니다. 첫째, **공학적 최적화(V3)**를 통해 제한된 자원으로도 높은 성능을 내는 모델을 구현했습니다. 둘째, **패러다임 혁신(R1 Zero 및 R1)**을 통해 감독 미세조정(SFT) 없이 순수 강화 학습만으로 모델의 추론 능력을 비약적으로 향상시키는 경로를 증명했습니다. 이는 모델 훈련의 비용과 효율성 문제를 동시에 해결하는 혁신적인 접근법입니다.
- 핵심 투자자 시사점: 딥시크는 기술적 파괴에 대한 고위험 고수익 투자 기회를 상징합니다. 오픈소스 전략은 빠른 시장 채택과 커뮤니티 기반의 개선을 촉진하는 동시에 직접적인 수익화를 복잡하게 만드는 양날의 검입니다. 투자 테제는 이들이 기술적 리더십을 지배적인 생태계나 수익성 높은 엔터프라이즈 서비스로 전환할 수 있는지에 달려 있습니다.
4.3. 엔터프라이즈 적용 선도자: 알리바바 메일(Alibaba Mail)
알리바바 메일은 성숙한 B2B 시장에서 AI를 어떻게 성공적으로 적용할 수 있는지를 보여주는 탁월한 사례입니다.
알리바바는 '통이치엔원', '딥시크' 등 다양한 내외부 대규모 모델을 자사의 이메일 서비스에 유연하게 통합했습니다. 이를 통해 단순히 이메일 요약이나 초안 작성과 같은 텍스트 처리 기능을 넘어, 이메일 내용을 분석하여 기업의 업무 프로세스를 자동화하는 단계로 나아가고 있습니다. 예를 들어, 특정 비즈니스 문의 메일을 자동으로 인식해 관련 부서의 RPA(로봇 프로세스 자동화) 워크플로우를 실행시키는 방식입니다. 이 사례는 기존 엔터프라이즈 솔루션에 AI를 접목하여 실질적인 부가 가치를 창출하는 성공 모델을 제시합니다.
- 핵심 투자자 시사점: 알리바바 메일은 성숙한 엔터프라이즈 시장에서 AI를 수익화하는 청사진입니다. 이는 가장 즉각적인 가치가 기초 모델 개발이 아닌, 동급 최고의 AI를 기존 워크플로우에 지능적으로 통합하여 실질적인 비즈니스 문제를 해결함으로써 창출될 수 있음을 증명하며, AI 애플리케이션 계층의 투자 타당성을 보여줍니다.
이처럼 성공적인 기업들의 사례를 통해 투자 기회를 구체화했습니다. 그러나 성공적인 투자의사결정을 위해서는 잠재적인 리스크를 면밀히 점검하는 과정이 반드시 필요합니다. 다음 장에서는 AI 투자 시 고려해야 할 주요 리스크 요인을 분석하겠습니다.
5. 투자 리스크 분석 및 고려사항
AI 기술에 대한 투자는 높은 잠재 수익만큼이나 다양한 리스크를 동반합니다. 특히 기술 자체의 결함에서 비롯되는 내재적 리스크와 기술이 사회에 적용되면서 발생하는 응용 리스크는 투자자가 반드시 인지하고 관리해야 할 핵심 요인입니다. 본 섹션은 이러한 주요 리스크를 체계적으로 분석하여 균형 잡힌 투자 시각을 제공하는 것을 목표로 합니다.
5.1. 내재적 기술 리스크 (내생 안전)
- 데이터 보안 리스크: 허가되지 않은 개인정보나 기업 기밀 데이터가 사용될 경우, 심각한 법적 문제와 브랜드 신뢰도 하락으로 이어질 수 있습니다.
- 알고리즘 안전 리스크: 모델 중독(Model Poisoning, 악의적인 데이터를 주입해 모델 성능을 저하)이나 프롬프트 주입(Prompt Injection, 교묘한 명령어로 모델의 안전장치를 우회)과 같은 공격에 취약할 수 있으며, 이는 예기치 않은 오작동이나 정보 유출의 원인이 될 수 있습니다.
- 모델 자체의 결함: AI가 사실과 다른 정보를 생성하는 '환각(Hallucination)' 현상이나, 학습 데이터의 편향성으로 인해 차별적인 결과를 내놓는 '알고리즘 편향(Bias)' 문제는 AI 서비스의 신뢰성을 근본적으로 훼손할 수 있는 중대한 리스크입니다.
- 애널리스트 노트: 실사 과정에서 투자 대상 기업의 레드팀(Red-teaming) 프로세스, 적대적 공격 방어 체계, 모델 거버넌스 프레임워크를 면밀히 검토해야 합니다. 강력한 내부 테스트 프로토콜이 없는 기업은 상당한 운영 및 평판 리스크를 안고 있습니다.
5.2. 응용 및 윤리적 리스크 (응용 안전)
- 허위 정보 확산: 생성형 AI 기술이 가짜뉴스, 딥페이크 등 허위 정보를 대량으로 생산하고 유포하는 데 악용될 경우, 심각한 사회적 혼란을 야기할 수 있습니다.
- 불법적 악용: AI 기술이 피싱, 사기, 사이버 공격과 같은 범죄 활동에 사용될 위험이 상존하며, 이는 기업과 개인에게 직접적인 피해를 줄 수 있습니다.
- 정보 고립(필터 버블) 심화: AI가 사용자 피드백을 바탕으로 추천 콘텐츠를 지속적으로 최적화하면서, 사용자의 인지적 편향을 강화하고 사회적 고립을 심화시킬 수 있습니다.
- 책임 및 권리 문제: AI가 생성한 콘텐츠의 저작권이 누구에게 있는지, AI의 잘못된 판단으로 인해 발생한 손해의 책임은 누가 져야 하는지에 대한 법적, 제도적 기준이 아직 명확하지 않습니다.
- 윤리적 문제: 사용자가 AI에 과도하게 정서적으로 의존하거나, 중요한 의사결정을 AI에 위임하면서 발생하는 인간의 주체성 상실 등 근본적인 윤리적 문제가 발생할 수 있습니다.
- 애널리스트 노트: 투자 대상 기업이 명확한 AI 윤리 가이드라인과 콘텐츠 관리 정책을 갖추고 있는지 평가하는 것이 중요합니다. 사회적 영향에 대한 깊은 이해와 책임감 있는 자세를 보여주는 기업이 장기적으로 지속 가능합니다.
5.3. 규제 환경의 불확실성
PwC의 자료에 따르면, 중국은 '생성형 인공지능 서비스 관리 잠정 방법'과 같은 규제를 도입하며 본격적인 AI 규제 신시대에 진입했습니다. 이러한 규제는 데이터 수집, 모델 학습, 서비스 출시에 이르기까지 기업 활동 전반에 직접적인 영향을 미칠 수 있습니다. 투자자는 투자 대상 기업이 변화하는 규제 환경에 어떻게 대응하고 있는지 지속적으로 모니터링하고 평가해야 합니다.
- 애널리스트 노트: 포트폴리오는 강력한 대정부 관계 팀을 보유하고, 변화하는 규제 요건에 맞춰 제품 로드맵을 조정하는 능력을 입증한 기업에 유리하게 구성되어야 합니다. 이러한 '규제 민첩성'은 중요한 비기술적 해자입니다.
지금까지 투자 결정에 앞서 고려해야 할 모든 잠재적 리스크를 검토했습니다. 이를 바탕으로, 최종적인 투자 결론과 구체적인 권고 사항을 다음 장에서 제시하겠습니다.
6. 결론 및 투자 권고
본 제안서는 중국 AI 시장이 거시 경제적 어려움 속에서도 정부의 강력한 지원과 파괴적인 기술 혁신을 바탕으로 여전히 강력한 성장 동력을 보유하고 있음을 분석했습니다. 특히, 자본의 흐름과 기술 발전 방향성을 고려할 때, 시각적 생성 AI 분야는 높은 성장 잠재력을 지닌 매력적인 초기 투자 기회를 제공하고 있음을 확인했습니다.
이러한 분석을 바탕으로 다음과 같은 투자 전략을 권고합니다.
- 핵심 투자 분야: 투자 포트폴리오의 핵심을 시각적 생성 AI 분야의 초기 단계 기업에 집중할 것을 권고합니다. 이는 시장 성장 초기 단계의 높은 잠재 수익률을 목표로 하는 전략입니다.
- 기업 선정 기준: 단순히 기술력만 보유한 기업보다는, 딥시크(DeepSeek)처럼 **강력한 기술적 해자(오픈소스 생태계, R&D 역량)**를 구축했거나, 바이트댄스(ByteDance)처럼 포괄적인 수직 통합 생태계를 통해 시장 지배력을 확보한 기업을 우선적으로 고려해야 합니다.
- 리스크 관리: 5장에서 분석한 내재적 기술 리스크, 응용 및 윤리적 리스크, 그리고 규제 환경의 불확실성을 충분히 인지해야 합니다. 투자 대상 기업을 선정할 때, 이러한 리스크에 대한 관리 및 대응 전략을 얼마나 체계적으로 갖추고 있는지 면밀히 평가하는 실사(Due Diligence) 과정이 필수적입니다.
본 제안서가 중국 AI 시장의 역동적인 변화 속에서 현명한 투자 기회를 모색하는 잠재 투자자 여러분의 성공적인 의사결정에 기여할 수 있기를 바랍니다.
대규모 언어 모델(LLM) 훈련 마스터하기: 단계별 완벽 가이드
서론: LLM의 잠재력을 깨우는 여정
대규모 언어 모델(LLM)은 이미 우리 삶의 많은 부분을 변화시키고 있지만, 그 진정한 잠재력은 범용적인 능력을 넘어 특정 목적에 맞게 최적화될 때 비로소 발현됩니다. LLM을 특정 분야의 전문가로 만들거나, 우리 조직의 고유한 데이터를 이해하는 조수로 만드는 과정은 단순한 사용을 넘어 '창조'의 영역으로 나아가는 핵심 단계입니다.
이 가이드는 범용 LLM이라는 강력한 원석을 데이터, 훈련, 최적화라는 도구를 사용해 여러분의 목적에 맞는 정교한 보석으로 세공하는 전 과정을 안내합니다. 모든 과정의 출발점인 데이터 준비부터 모델의 기초 체력을 기르는 증분 사전 훈련, 특정 작업에 맞춤형 전문가로 만드는 미세 조정, 그리고 실제 서비스 적용을 위한 고급 최적화까지, LLM의 잠재력을 완전히 깨우는 전체 여정을 단계별로 안내합니다. 이 가이드를 통해 여러분은 LLM이 어떻게 학습하고 진화하는지에 대한 깊이 있는 통찰을 얻게 될 것입니다.
1. 첫걸음: 모델의 성능을 좌우하는 데이터 준비
성공적인 LLM 훈련의 성패는 90% 이상 데이터에 달려있다고 해도 과언이 아닙니다. 마치 좋은 재료 없이 훌륭한 요리를 만들 수 없듯이, 고품질의 데이터 없이는 고성능 모델을 기대하기 어렵습니다. 아래 경로에서 볼 수 있듯, 데이터 처리 단계는 전체 훈련 파이프라인의 가장 첫 단추이며, 이 단계의 완성도가 최종 결과물의 품질을 결정합니다.
사전 훈련된 대규모 모델 능력 구현 경로 데이터 처리 → 증분 사전 훈련 → 미세 조정 → 모델 배포
데이터 준비 과정은 요리에 비유할 수 있으며, 다음의 세 가지 핵심 단계로 구성됩니다.
- 데이터 수집 (Data Acquisition) 이 단계는 요리의 '원재료'를 모으는 것과 같습니다. 공개 데이터셋부터 기업 내부의 고유 문서까지, 훈련 목표에 부합하는 모든 종류의 데이터를 확보합니다.
- 데이터 정제 (Data Cleaning) 수집된 데이터에서 부정확하거나 불필요한 부분을 제거하는, 마치 상하거나 불필요한 부분을 '손질'하는 과정입니다. 이를 통해 모델이 잘못된 패턴을 학습하는 것을 방지합니다.
- 데이터 전처리 (Data Preprocessing) 손질된 재료를 셰프(모델)가 요리하기 좋도록 '다듬고 양념'하는 단계입니다. 텍스트를 토큰(token) 단위로 분할하는 등 모델의 학습 효율을 극대화하는 형태로 데이터를 가공합니다.
이처럼 체계적으로 준비된 고품질 데이터는 모델이 세상의 지식을 이해하고 언어적 패턴을 익히는 단단한 기반이 됩니다. 이제 이 기반 위에 특정 영역의 전문성을 더하는 다음 단계로 나아가 보겠습니다.
2. 능력 강화: 증분 사전 훈련 (Incremental Pre-training)
증분 사전 훈련(Incremental Pre-training) 또는 **후훈련(Post-training)**은 이미 방대한 데이터로 학습된 기존의 사전 훈련 모델(Pre-trained Model)에 새로운 데이터를 추가로 학습시켜 특정 분야의 지식을 보강하거나 전반적인 기초 능력을 강화하는 과정입니다. 이는 마치 대학 졸업생에게 특정 전문 분야의 심화 교육을 시키는 것과 같습니다.
이 기법은 모델의 기반 능력을 한 단계 끌어올리는 효과적인 방법으로, 다음과 같은 실제 사례를 통해 그 효과를 확인할 수 있습니다.
- GPT-o 시리즈: 대규모 강화 학습(RL) 알고리즘을 적용하여 모델이 복잡한 문제를 해결할 때 내부적인 '사고 사슬(Chain of Thoughts, CoT)'을 더 효과적으로 활용하도록 훈련되었습니다.
- DeepSeek R1: 기반 모델에 대규모 강화 학습을 포함한 후훈련을 적용하여, 복잡한 과제에 대한 추론(reasoning) 능력을 극대화한 대표적인 사례입니다.
증분 사전 훈련을 통해 모델의 범용적인 기초 체력을 강화했다면, 이제는 특정 임무에 완벽하게 들어맞도록 모델을 정교하게 '조각'하는 미세 조정 단계로 넘어갈 차례입니다.
3. 맞춤형 전문가로 변신: 미세 조정 (Fine-Tuning) 기법
미세 조정의 핵심 목표는 이미 뛰어난 범용 LLM을 특정 작업이나 전문 영역에 최적화하여 '만능 재주꾼'을 '특화된 전문가'로 탈바꿈시키는 것입니다. 소량의 특정 데이터셋을 활용해 모델을 추가 훈련함으로써, 원하는 작업에 대한 성능을 극대화하고 특정 지식을 주입할 수 있습니다.
3.1. 미세 조정의 두 가지 접근법: 전체 파라미터 vs. 파라미터 효율적 미세 조정
미세 조정은 크게 두 가지 전략으로 나뉩니다. 어떤 파라미터(모델의 학습 가능한 변수)를 얼마나 조정할지에 따라 접근 방식이 달라지며, 각각의 장단점이 뚜렷합니다.
| 접근법 | 핵심 원리 | 주요 장단점 |
| 전체 파라미터 미세 조정 | 모델의 모든 계층에 있는 모든 파라미터를 새로운 데이터에 맞춰 재조정하는 전통적인 방식입니다. | 장점: 잠재적으로 가장 높은 성능을 달성할 수 있습니다.<br>단점: 막대한 계산 자원과 시간이 필요합니다. |
| 파라미터 효율적 미세 조정 (PEFT) | 모델의 일부 파라미터만 선택적으로 조정하거나, 소수의 새로운 파라미터를 추가하여 훈련하는 효율적인 방식입니다. | 장점: 계산 비용이 매우 낮고 훈련 속도가 빠릅니다.<br>단점: 경우에 따라 전체 미세 조정보다 성능이 약간 낮을 수 있습니다. |
3.2. 핵심 미세 조정 기술 탐구
다양한 미세 조정 기법 중 가장 대표적인 기술들은 다음과 같습니다.
- 지도 미세 조정 (Supervised Fine-Tuning, SFT) 특정 작업에 대해 '질문과 정답'이 명확하게 라벨링된 데이터를 사용하여 모델을 훈련시키는 방식입니다. 예를 들어, 법률 문서 요약 데이터셋으로 SFT를 진행하면 모델은 법률 문서 요약에 특화된 능력을 갖추게 됩니다. 이 방식은 모델이 특정 작업의 패턴을 직접적으로 학습하도록 가르치는 가장 직관적인 방법입니다.
- 인간 피드백 기반 강화 학습 (RLHF) 모델이 생성하는 결과물이 단순히 '정답'인지를 넘어, 인간의 선호도와 가치에 더 부합하도록 만드는 고도화된 기법입니다. RLHF는 주로 다음의 3단계 과정을 거칩니다.
- SFT 모델 준비: 먼저 지도 미세 조정을 통해 특정 작업을 수행할 수 있는 기본 모델을 준비합니다.
- 보상 모델(RM) 훈련: 인간 평가자가 모델이 생성한 여러 답변에 대해 선호도 순위를 매깁니다. 이 데이터를 학습하여 어떤 답변이 '더 좋은' 답변인지를 판단하는 **보상 모델(Reward Model)**을 만듭니다.
- 강화 학습(RL) 최적화: SFT 모델이 다양한 답변을 생성하게 하고, 보상 모델이 각 답변에 점수를 매깁니다. 모델은 더 높은 보상(점수)을 받는 방향으로 자신의 답변 생성 정책을 스스로 최적화해 나갑니다.
- 이 기법은 특히 코딩이나 수학처럼 정답의 우수성을 비교적 명확하게 평가하고 보상 피드백을 주기 용이한 분야에서 강력한 효과를 보이며, 모델의 논리적 사고 능력을 크게 향상시킵니다.
- LoRA (Low-Rank Adaptation) 파라미터 효율적 미세 조정(PEFT)의 가장 대표적인 기법입니다. LoRA는 기존 모델의 가중치는 그대로 둔 채, 아주 적은 수의 파라미터로 구성된 작은 행렬(어댑터)을 추가하여 이 부분만 훈련합니다. 이 접근법은 계산 비용을 크게 절감하면서도 전체 파라미터를 미세 조정하는 것과 유사한 높은 성능을 달성할 수 있어 매우 실용적입니다.
이제 모델을 특정 작업에 맞게 성공적으로 미세 조정했습니다. 다음 단계에서는 모델이 최신 정보를 반영하거나, 더 가볍고 빠르게 작동하도록 만들어 실제 서비스에 효율적으로 배포하는 고급 전략들을 살펴보겠습니다.
4. 성능 극대화: 고급 최적화 및 배포 전략
미세 조정을 마친 모델을 실제 서비스에 적용하기 전, 성능을 한층 더 끌어올리거나 운영 효율성을 높이기 위한 고급 전략들이 있습니다. 대표적인 두 가지 기법은 다음과 같습니다.
4.1. 외부 지식 활용: 검색 증강 생성 (RAG)
**검색 증강 생성(Retrieval-Augmented Generation, RAG)**은 모델이 답변을 생성할 때 자신의 내장된 지식에만 의존하는 한계를 극복하기 위한 기술입니다. 사용자의 질문이 들어오면, RAG 시스템은 먼저 외부 데이터베이스나 문서 저장소에서 가장 관련성 높은 정보를 실시간으로 검색합니다. 그리고 검색된 최신 정보를 LLM에게 참고 자료로 함께 전달하여, 이를 바탕으로 더 정확하고 풍부한 답변을 생성하도록 합니다. 이는 모델이 부정확한 정보를 지어내는 **'환각 현상(Hallucination)'**을 효과적으로 줄이고, 답변의 신뢰도를 극대화하는 핵심 전략입니다.
4.2. 모델 경량화: 증류 (Distillation)
**모델 증류(Distillation)**는 거대한 고성능 모델의 지식을 더 작고 효율적인 모델에게 전수하는 기법입니다. 이 과정은 마치 지식이 풍부한 **'선생님 모델(대규모 모델)'**이 간결하게 핵심을 가르쳐 **'학생 모델(소규모 모델)'**을 훈련시키는 것과 같습니다. 학생 모델은 선생님 모델의 결과뿐만 아니라, 정답에 도달하는 '과정'까지 학습하여 적은 계산 자원으로도 선생님 모델과 유사한 성능을 낼 수 있습니다. 이 기법은 모델을 압축하고 서비스 배포 비용을 절감하는 데 매우 효과적이어서, 모바일 기기나 엣지 디바이스에 AI 모델을 탑재할 때 핵심적인 역할을 합니다.
결론: 나만의 LLM을 향한 길
지금까지 우리는 하나의 범용 대규모 언어 모델이 특정 목적에 맞는 강력한 도구로 재탄생하는 전 과정을 살펴보았습니다. 모든 것의 시작인 데이터 준비부터, 모델의 기초 체력을 다지는 증분 사전 훈련, 특정 분야의 전문가로 만드는 다양한 미세 조정 기법(SFT, RLHF, LoRA), 그리고 마지막으로 성능과 효율을 극대화하는 RAG와 증류 같은 고급 전략에 이르기까지, 각 단계는 유기적으로 연결되어 LLM의 잠재력을 최대한으로 이끌어냅니다.
LLM 훈련은 한 번에 끝나는 여정이 아니라, 지속적인 데이터와 피드백을 통해 모델을 성장시키는 과정입니다. 이 가이드에서 다룬 원칙들은 그 성장의 첫걸음을 내딛는 단단한 발판이 될 것입니다. 이러한 지식은 여러분이 단순히 AI를 사용하는 소비자를 넘어, 자신만의 아이디어와 데이터를 바탕으로 특화된 AI 모델을 직접 만들어나가는 창조자가 될 수 있는 길을 열어줄 것입니다.

AI 신경망 아키텍처의 진화: 초심자를 위한 핵심 가이드
서론: 인공지능의 뼈대를 만나다
인공지능 신경망 아키텍처는 마치 다양한 건물을 짓기 위한 '설계도'와 같습니다. 어떤 설계도를 사용하느냐에 따라 주택, 사무실, 공장 등 건물의 용도와 기능이 달라지듯, 어떤 아키텍처를 선택하느냐에 따라 AI는 이미지를 인식하고, 글을 쓰거나, 새로운 이미지를 창조하는 등 각기 다른 능력을 갖게 됩니다. 이 설계도들이 어떻게 발전해왔는지 이해하는 것은 인공지능이라는 거대한 건물이 어떤 기초 위에 세워졌는지 파악하는 것과 같습니다. 이 문서는 AI를 처음 배우는 여러분이 신경망 아키텍처의 핵심적인 발전 과정을 한눈에 파악하고, 각 기술의 특징과 역할을 명확히 이해할 수 있도록 돕는 것을 목표로 합니다.
1. 기본의 시작: 공간과 순서를 이해하는 모델 (CNN & RNN)
초기 인공지능 모델들은 세상의 데이터를 두 가지 기본 속성, 즉 '공간'과 '순서'를 중심으로 이해하기 시작했습니다.
CNN (Convolutional Neural Network) 소개
CNN은 **'공간 구조'**를 가진 데이터를 처리하는 데 특화된 아키텍처입니다. 사진 속 객체들의 배치나 형태처럼, 데이터 요소 간의 공간적 관계가 중요할 때 강력한 성능을 발휘합니다. 바로 이 특징 때문에 CNN은 이미지 속에서 특징을 효과적으로 추출하여 다음과 같은 분야에서 뛰어난 성과를 보입니다.
- 이미지 인식
- 목표물 탐지
- 이미지 분할
RNN (Recurrent Neural Network) 소개
RNN은 문장이나 음성처럼 **'시간 순서'**가 중요한 데이터를 처리하도록 설계되었습니다. 단어의 순서에 따라 문장의 의미가 완전히 달라지듯, 데이터의 앞뒤 관계와 연속성을 파악하는 데 최적화되어 있습니다. 초기 RNN은 긴 문장이나 데이터의 앞부분을 기억하는 데 어려움이 있었지만, 이를 개선한 LSTM과 같은 아키텍처가 등장하며 순차 데이터 처리 능력이 크게 향상되었습니다. 이러한 특성 덕분에 RNN은 다음과 같은 분야에서 널리 활용됩니다.
- 자연어 처리
- 음성 인식
- 기계 번역
핵심 비교
CNN과 RNN은 AI의 기초를 다진 핵심 아키텍처이지만, 그 역할과 접근 방식에는 명확한 차이가 있습니다.
| 구분 | CNN (합성곱 신경망) | RNN (순환 신경망) |
| 핵심 아이디어 | 데이터의 공간적 특징을 효과적으로 추출 | 데이터의 시간적, 순차적 관계를 처리 |
| 주요 처리 데이터 | 공간 구조를 가진 데이터 (예: 이미지) | 시간 순서가 중요한 데이터 (예: 텍스트, 음성) |
| 대표 적용 분야 | 이미지 인식, 목표물 탐지, 이미지 분할 | 자연어 처리, 음성 인식, 기계 번영 |
요약 및 통찰
CNN과 RNN은 오늘날에도 여전히 "소형 모델" 아키텍처의 형태로 다양한 분야에서 널리 사용되며 인공지능 기술의 중요한 기반이 되고 있습니다.
학습 연결고리
CNN과 RNN이 기존 데이터를 훌륭하게 분석했지만, AI 연구의 다음 목표는 단순히 데이터를 이해하는 것을 넘어 현실을 모방한 새로운 데이터를 창조하는 것이었습니다.
2. 창조의 시대: 데이터를 생성하는 모델 (GAN & Diffusion)
AI가 단순히 분석가를 넘어 창작가의 역할을 하게 된 것은 생성 모델의 등장 덕분입니다. 주어진 데이터를 분석하는 데 뛰어났던 초기 모델들의 한계를 넘어, AI는 이제 아무것도 없는 상태에서 새로운 데이터를 직접 만들어내는 시대로 진입했습니다.
GAN (Generative Adversarial Network) 소개
2014년에 등장한 GAN은 딥러닝이 **'생성 모델 연구'**라는 새로운 단계로 진입했음을 알린 혁신적인 아키텍처입니다. GAN의 핵심 원리는 두 개의 신경망, 즉 데이터를 만들어내는 **'생성자(Generator)'**와 그것이 진짜인지 가짜인지 판별하는 **'판별자(Discriminator)'**가 서로 경쟁하며 학습하는 것입니다. 이 경쟁을 통해 생성자는 점점 더 실제와 가까운 데이터를 만들어내는 능력을 갖추게 됩니다.
- 주요 활용 분야
- 샘플 데이터 생성
- 이미지 생성 및 복원
- 이미지 변환
- 텍스트 생성
Diffusion Model 소개
Diffusion 모델은 **'노이즈(noise)로부터 고품질 데이터를 생성'**하는 확률 기반의 생성 모델입니다. 이 모델은 마치 깨끗한 이미지에 노이즈를 점차 추가하여 완전히 무질서한 상태로 만든 뒤, 그 과정을 거꾸로 되짚어 노이즈에서부터 다시 원래의 깨끗한 이미지를 복원하는 방식으로 작동합니다. 이 과정을 통해 매우 정교하고 품질 높은 결과물을 만들어낼 수 있습니다.
- 주요 활용 분야
- 이미지 생성 및 복원
- 이미지 변환
- 비디오 생성
학습 연결고리
이미지나 텍스트를 생성하는 능력은 AI의 가능성을 크게 확장했지만, 기술은 여기서 멈추지 않았습니다. 이제 인간의 복잡한 언어를 더 깊이 이해하고 방대한 지식을 다룰 수 있는, 그야말로 '거인'과 같은 새로운 아키텍처가 등장할 차례였습니다.
3. 거인의 등장: 대규모 모델 시대의 개척자 (Transformer)
오늘날 우리가 경험하는 AI 혁신의 대부분은 Transformer 아키텍처의 등장에서 시작되었습니다. RNN과 같은 순차적 모델은 데이터를 하나씩 순서대로 처리해야 했기 때문에 학습 속도가 느렸고, 긴 문장에서 앞뒤 단어 간의 중요한 관계(장기 의존성)를 파악하는 데 한계가 있었습니다. Transformer는 이러한 한계를 극복하기 위해 탄생했습니다.
혁신적인 등장
2017년, Google은 **'자기 주의 메커니즘(self-attention mechanism)'**에 기반한 Transformer 아키텍처를 세상에 공개했습니다. 이는 문장 속 모든 단어의 관계를 한 번에 계산하여 어떤 단어가 다른 단어에 얼마나 중요한지를 파악하는 방식으로, 문맥을 더 깊고 빠르게 이해할 수 있게 했습니다. 이 혁신적인 방식은 대규모 병렬 처리를 가능하게 했고, 이는 대규모 모델(Large Model) 시대의 기술적 토대가 되었습니다.
발전의 이정표
Transformer의 등장은 AI 역사에 중요한 이정표를 남기며 대규모 모델 시대를 본격적으로 열었습니다.
- 2017년: Google, Transformer 아키텍처 발표.
- 2018년: OpenAI의 GPT-1과 Google의 BERT 대규모 모델 발표.
- 2022년 11월: GPT-3.5 기반의 ChatGPT가 출시되며 대규모 모델 시대의 대중화를 이끌었습니다.
핵심 의의와 확장성
Transformer는 단순히 하나의 모델을 넘어 **'대규모 모델 사전 훈련 알고리즘의 기초'**가 되었습니다. 그 구조적 유연성과 강력한 성능 덕분에 텍스트 처리뿐만 아니라, 엔드투엔드 음성 대규모 모델 개발 및 시각(DiT, ViT) 분야로 빠르게 확장되며 AI 기술의 범용성을 증명하고 있습니다.
학습 연결고리
지금까지 우리는 공간과 순서를 이해하는 기본 모델부터 데이터를 창조하는 생성 모델, 그리고 대규모 언어 모델의 시대를 연 Transformer까지 주요 아키텍처의 발전 과정을 살펴보았습니다. 이제 이 모든 것을 한눈에 정리해 보겠습니다.
4. 최종 정리: 한눈에 보는 신경망 아키텍처 발전사
각 아키텍처는 특정 문제를 해결하기 위해 등장했으며, 이들의 발전이 모여 오늘날의 강력한 인공지능을 만들었습니다.
| 아키텍처 (Architecture) |
핵심 개념 (한 줄 요약) | 주요 활용 분야 (Primary Application) |
| CNN | 이미지와 같은 데이터의 공간적 특징을 추출하는 데 특화된 모델 | 이미지 인식, 목표물 탐지, 이미지 분할 |
| RNN | 텍스트나 음성처럼 시간적 순서가 중요한 데이터를 처리하는 모델 | 자연어 처리, 음성 인식, 기계 번역 |
| GAN | '생성자'와 '판별자'가 서로 경쟁하며 학습하여 새로운 데이터를 생성하는 모델 | 이미지 생성/복원, 이미지 변환, 텍스트 생성 |
| Diffusion | 데이터를 무질서하게 만든 후 다시 복원하는 과정을 통해 고품질 데이터를 생성하는 모델 | 이미지/비디오 생성, 이미지 복원 및 변환 |
| Transformer | **'자기 주의 메커니즘'**을 통해 데이터 전체의 관계를 파악하는 대규모 모델의 기반 | 대규모 언어 모델, 텍스트 생성, 음성 및 시각 처리 |
인공지능 신경망 아키텍처의 발전은 지금 이 순간에도 계속되고 있습니다. 오늘 살펴본 핵심 개념들은 빠르게 변화하는 AI 기술의 흐름을 이해하고 미래를 예측하는 데 중요한 첫걸음이 될 것입니다. 이 지식을 바탕으로 인공지능의 무한한 가능성을 계속 탐험해 나가시길 바랍니다.
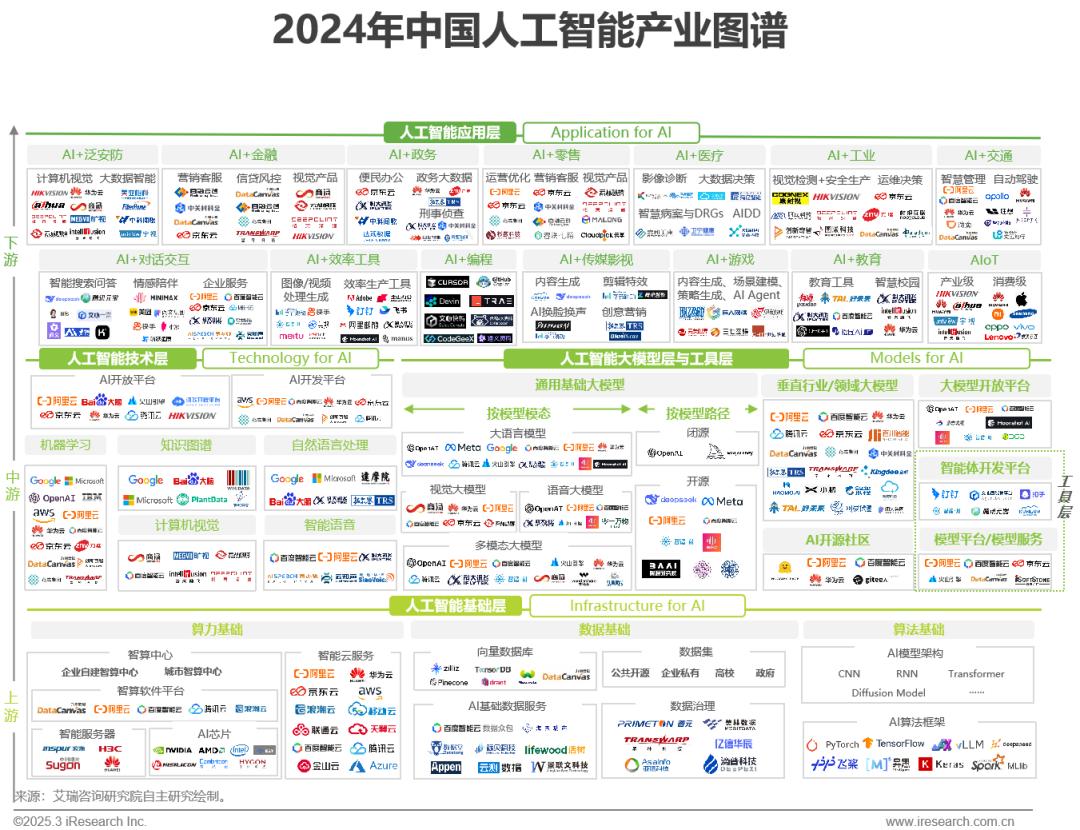
中国人工智能产业链发展研究报告 2025
一、中国AI+行业进程加速渗透 决策式AI与生成式AI的共同赋能,生成式AI加速内容产业的渗透进程人工智能技术正与人类经济生产活动的主要环节达成紧密结合,提供生产办公效率提升、运营管理
ihe.cczu.edu.cn
AI 산업 보고서에서 발견한 5가지 예상 밖의 진실
매일같이 쏟아지는 인공지능(AI) 관련 뉴스 속에서 우리는 종종 기술의 본질적인 변화를 놓치곤 합니다. 화려한 신제품 발표나 대규모 투자 소식 뒤에 가려진, 산업의 근본적인 흐름을 파악하기란 쉽지 않습니다.
이 글은 소음을 걷어내고 AI 산업의 진짜 모습을 보여드리고자 합니다. 최신 '2024년 중국 AI 산업 보고서'를 깊이 분석하여, 일반적인 통념을 깨는 다섯 가지 놀랍고도 중요한 사실을 정리했습니다. 이 글을 통해 AI가 우리 비즈니스와 사회를 어떻게 바꾸고 있는지에 대한 새로운 통찰을 얻게 될 것입니다.
1. 경기 둔화가 오히려 AI 도입을 가속화하고 있다
일반적으로 경제가 어려워지면 기업들은 투자를 줄이고 신기술 도입에 소극적으로 변할 것이라 생각합니다. 하지만 AI 산업에서는 정반대의 현상이 나타나고 있습니다. 보고서에 따르면, 중국의 GDP 성장률 둔화와 2023년 0.2%를 기록한 CPI(소비자물가지수) 성장률에서 나타나듯 디플레이션 압력이 오히려 기업들의 AI 도입을 촉진하는 기폭제가 되고 있습니다.
물론 경기 둔화는 투자 감소와 시장 수요 위축이라는 어려움을 가져옵니다. 그러나 바로 이 위기 상황 속에서 AI의 진정한 가치가 부각되고 있습니다. 생산 효율성을 극대화하고 새로운 비즈니스 모델을 창출하는 AI의 능력은 이제 경제 회복과 성장을 위한 핵심 도구로 인식되고 있습니다.
이는 AI가 더 이상 호황기에 누리는 사치품이 아니라, 경제적 어려움을 극복하기 위한 필수적인 기반 기술로 자리 잡았음을 의미합니다. 위기가 혁신을 낳는다는 격언이 AI 산업에서 현실화되고 있는 것입니다.
2. 가장 큰 혁신은 '지루한' 기술에서 일어나고 있다
세상을 바꿀 것 같은 화려한 생성형 AI 앱들이 주목받는 동안, 가장 실질적인 혁신은 우리가 매일 사용하는 '지루한' 기업용 도구에서 조용히 일어나고 있습니다. 대표적인 사례가 바로 딩톡(DingTalk) 산하의 기업용 이메일 서비스인 '알리메일(Alibaba Mail)'입니다.
보고서에 따르면, 알리메일은 AI를 단순히 이메일 작성이나 번역 같은 보조 기능에 활용하는 것을 넘어, 이메일 데이터를 구조화된 '메타데이터(metadata)'(즉, '계약 제안서'나 '송장 #12345'처럼 다른 데이터를 설명하는 데이터)로 변환하고 있습니다. 예를 들어, 계약서가 첨부된 이메일이나 비용 승인 요청 이메일을 AI가 분석하여 핵심 정보를 추출하고, 이를 정형화된 데이터로 만드는 것입니다.
이는 받은 편지함을 수동적인 소통 기록 보관소에서 역동적이고 자동화된 운영 허브로 탈바꿈시킵니다. 이는 AI가 단순히 직원들의 업무 속도를 높이는 데 그치지 않고, 그 업무가 속한 핵심 비즈니스 프로세스 자체를 근본적으로 재설계하고 있음을 보여주는 중대한 변화입니다.
3. 코딩의 미래는 '모두를 위한 코딩'이다
AI 코딩 도구의 발전은 소프트웨어 개발의 미래가 소수 전문가의 영역을 벗어나고 있음을 명확히 보여줍니다. 초기의 AI 코딩 도구가 전문 개발자를 돕는 '조수(Copilot)'의 역할에 머물렀다면, 이제는 스스로 작업을 수행하는 '에이전트(Agent)'로 진화하고 있습니다.
보고서는 영상 편집 소프트웨어의 발전 과정에서 설득력 있는 유사점을 찾아냅니다. 과거 전문가용 툴이 소수만 다룰 수 있었지만, 캡컷(剪映)과 같이 사용자 친화적인 앱이 등장하며 영상 제작의 민주화를 이끌고 새로운 크리에이터 경제를 탄생시켰듯, AI 코딩 에이전트 역시 비전문가들의 프로그래밍 진입 장벽을 극적으로 낮추고 있습니다.
이러한 '프로그래밍의 민주화'는 소프트웨어 생태계를 근본적으로 바꿀 잠재력을 가집니다. 더 다양하고 개인화된 소프트웨어가 폭발적으로 증가하게 될 것이며, 이는 제품이 만들어지는 방식과 만드는 주체를 완전히 재정의할 것입니다.
4. 오픈소스가 AI 산업의 새로운 전쟁터가 되고 있다
AI 산업의 패권 경쟁이 거대 기업들의 폐쇄적인 모델 개발에만 달려있다는 생각은 이제 낡은 것이 되었습니다. 보고서는 '딥시크(DeepSeek)'와 같은 기업들이 강력한 성능의 모델을 오픈소스로 공개하며 산업의 판도를 바꾸고 있다고 분석합니다.
딥시크는 새로운 훈련 패러다임을 개척하고 있습니다. 예를 들어, 초기 모델인 DeepSeek R1 Zero는 순수 강화 학습 경로의 실행 가능성을 입증했습니다. 이 방식은 대규모의 값비싼 인간 라벨링 데이터에 의존하는 전통적인 지도 미세 조정(SFT) 단계를 건너뛰고도 강력한 추론 능력을 달성할 수 있습니다. 그리고 이들은 모델의 소스 코드와 기술적인 세부 사항까지 공개하는 과감한 전략을 채택했습니다.
이 전략이 강력한 이유는 오픈소스가 전 세계 개발자 커뮤니티를 끌어들이기 때문입니다. 개발자들은 자발적으로 버그를 찾고, 모델을 개선하며, 새로운 활용 사례를 만들어냅니다. 이는 기업 혼자서는 결코 이룰 수 없는 빠르고 강력한 선순환 생태계를 구축하며, 오픈소스가 AI 산업의 가장 중요한 전략적 자산이자 새로운 전쟁터가 되었음을 증명합니다.
5. '구독'의 시대가 가고 '성과 기반 지불'의 시대가 온다
현재 대부분의 AI 서비스는 매월 또는 매년 요금을 내는 SaaS(서비스형 소프트웨어) 구독 모델로 제공됩니다. 하지만 보고서는 이를 과도기적 단계로 규정하며, 더 진화된 비즈니스 모델이 다가오고 있다고 예측합니다. 바로 '성과 기반 지불(pay-for-performance)' 모델입니다.
미래의 기업들은 특정 AI 도구에 가입하는 대신, 특정 과업을 수행할 'AI 에이전트'를 고용하게 될 것입니다. 그리고 그 비용은 AI 에이전트가 성공적으로 업무를 완수했는지, 그 결과물의 품질이 어떠했는지에 따라 지불됩니다. 예를 들어, '월간 시장 분석 보고서 작성'이라는 업무를 맡기고, 완성된 보고서의 품질에 따라 비용을 내는 식입니다.
하지만 이러한 전환에는 해결해야 할 과제도 존재합니다. 보고서는 이 새로운 모델이 '기업의 현금 흐름, AI 제품의 효과, 가치 기반 가격 책정 평가에 더 높은 요구사항을 제기한다'고 지적합니다. 이는 성과 기반 지불 모델이 논리적인 종착점이긴 하지만, 그 구현을 위해서는 AI의 직접적인 비즈니스 영향을 측정하고 증명하기 위한 새로운 프레임워크가 필요함을 시사합니다.
결론
헤드라인을 장식하는 뉴스 너머에서 AI 산업은 훨씬 더 미묘하고 예상치 못한 방식으로 진화하고 있습니다. 경제 위기는 AI 도입의 촉매제가 되고, 가장 오래된 기술이 혁신의 중심에 서고 있으며, 코딩과 비즈니스 모델의 경계는 허물어지고 있습니다.
이러한 변화의 흐름을 이해하는 것은 미래를 준비하는 모든 비즈니스 리더에게 필수적입니다. 마지막으로 한 가지 질문을 던지며 글을 마칩니다.
"AI가 단순한 조수를 넘어 자율적인 에이전트로 발전함에 따라, 당신의 업무나 일상에서 가장 먼저 완전히 변화될 부분은 무엇이라고 생각하십니까?"

2024년 중국 인공지능 산업 연구 학습 가이드
단답형 퀴즈
각 질문에 대해 2-3문장으로 간결하게 답변하세요.
- 최근 중국의 경제 상황이 인공지능(AI) 산업에 미친 이중적인 영향은 무엇입니까?
- CNN과 RNN 아키텍처의 주요 차이점과 각각의 대표적인 적용 분야는 무엇입니까?
- 대규모 모델(Large Model) 시대의 기반을 마련한 Transformer 아키텍처의 혁신적인 핵심 메커니즘은 무엇입니까?
- 검색 증강 생성(RAG) 기술이란 무엇이며, 대규모 언어 모델의 성능을 어떻게 향상시키나요?
- AI 코딩 제품은 'Copilot'에서 'Agent'로 어떻게 진화하고 있으며, 이러한 변화가 프로그래밍 분야에 어떤 잠재적 영향을 미칠 것으로 예상됩니까?
- 1세대 음성 대형 모델(계단식 아키텍처)과 2세대(엔드투엔드 아키텍처)의 장단점을 비교 설명하세요.
- 2024년 시각 모달리티 분야의 투자 동향에 따르면, '판별 중심의 머신 비전'과 '생성 중심의 AI 이미지/비디오' 두 분야의 성숙도와 투자 현황은 어떻게 다른가요?
- 바이트댄스(ByteDance)의 AI 제품 매트릭스는 어떤 4단계 구조로 이루어져 있습니까? 각 단계의 역할을 간략히 설명하세요.
- DeepSeek이 모델의 성능과 비용 문제를 해결하기 위해 채택한 핵심 전략과 기술 혁신은 무엇입니까?
- AI가 직면한 안전 문제를 '내재적 안전'과 '응용 안전' 두 가지로 나누어 설명하고, 각각의 구체적인 위험 사례를 한 가지씩 제시하세요.
퀴즈 정답
- 최근 중국 경제는 소비자물가지수(CPI) 하락과 같은 디플레이션 압력을 겪고 있습니다. 이는 투자 감소 및 시장 수요 위축으로 AI 산업에 부정적 영향을 주었지만, 동시에 AI 기술이 생산 효율성을 높이고 새로운 비즈니스 모델을 창출하여 경제 회복을 돕는 기회 요인으로도 작용하고 있습니다.
- CNN(합성곱 신경망)은 이미지 인식과 같이 공간 구조를 가진 데이터를 처리하는 데 적합하고, RNN(순환 신경망)은 자연어 처리나 음성 인식처럼 시간 순서 관계가 있는 데이터를 처리하는 데 특화되어 있습니다. 두 아키텍처는 때로 결합되어 더 복잡한 모델 구조를 형성하기도 합니다.
- Transformer 아키텍처의 혁신적인 핵심은 '자기 주의(self-attention) 메커니즘'에 있습니다. 이 메커니즘을 기반으로 하여 Google이 2017년에 이 구조를 제안했고, 이는 대규모 모델 사전 훈련 알고리즘 아키텍처의 기초를 다졌습니다.
- 검색 증강 생성(RAG)은 외부 지식 베이스를 활용하여 관련 정보를 검색하고, 이를 대규모 모델의 생성 능력과 결합하는 기술입니다. 이를 통해 모델이 생성하는 답변의 정확성과 풍부함을 향상시킬 수 있습니다.
- AI 코딩 제품은 초기 코드 완성을 돕는 'Copilot'에서, 복잡한 작업을 자율적으로 수행하는 'Agent'로 진화하고 있습니다. 이러한 진화는 프로그래밍의 문턱을 낮춰 비전문가들의 참여를 유도하고, 소프트웨어 개발 생태계를 더욱 다양하고 개인화된 방향으로 이끌 잠재력을 가집니다.
- 1세대 계단식 아키텍처는 제어 가능성과 정확성이 높지만 지연 시간이 길다는 단점이 있습니다. 반면 2세대 엔드투엔드 아키텍처는 지연 시간이 짧고 범용성이 좋지만, 제어 가능성과 정확성이 상대적으로 낮고 '환각(hallucination)' 문제를 일으킬 수 있습니다.
- '판별 중심의 머신 비전' 분야는 상업적으로 더 성숙하여 후기 단계(D+ 라운드 등) 투자가 이루어지는 반면, '생성 중심의 AI' 분야는 2023년 이후 설립된 신생 기업이 다수이며 투자가 초기 단계(C 라운드 이전)에 집중되어 있습니다. 이는 자본 시장이 머신 비전의 상업적 성숙도를 더 높게 평가하고 있음을 보여줍니다.
- 바이트댄스의 AI 제품 매트릭스는 4단계로 구성됩니다. 1) 기초 대형 모델(자체 개발한 Doubao 시리즈), 2) 대형 모델 개발 플랫폼(Volcano Ark), 3) 에이전트 개발 플랫폼(Coze/HiAgent), 4) 대형 모델 응용 계층(다양한 사용자 및 기업용 도구)입니다.
- DeepSeek은 모델 가중치, 기술 논문, 훈련 세부 정보 등을 공개하는 '오픈소스 전략'을 채택했습니다. 또한, 공학적 최적화(DeepSeek V3)를 통해 저비용 고효율 훈련을 실현하고, 순수 강화 학습 경로(DeepSeek R1 Zero)를 통해 인공적인 데이터 라벨링 없이 모델의 추론 능력을 향상시키는 패러다임 혁신을 이루었습니다.
- '내재적 안전'은 데이터 및 알고리즘 자체의 위험을 의미하며, '모델 환각(Model Hallucination)' 즉, 사실과 다른 내용을 생성하는 것이 그 예입니다. '응용 안전'은 AI 기술이 사회에 미치는 영향과 윤리적 문제로, AI를 이용한 '허위 정보 전파'가 대표적인 사례입니다.
서술형 에세이 질문
다음 질문들에 대해 자료에 근거하여 심층적으로 논하시오.
- 자료에 나타난 중국의 거시 경제 지표(GDP, CPI)와 대중의 AI에 대한 인식 변화를 종합하여, 중국 AI 산업이 직면한 사회·경제적 환경의 기회와 위협 요인에 대해 논하시오.
- CNN/RNN부터 Transformer, Diffusion, 그리고 다중모달 모델(MLLM, DiT)에 이르기까지 AI 모델 아키텍처의 발전 과정을 설명하고, 각 단계의 기술적 돌파가 AI 응용 분야(예: AI 코딩, AI 음성, AI 비전)에 어떤 구체적인 변화를 가져왔는지 분석하시오.
- AI 제품의 주요 상업화 모델(프로젝트 기반, MaaS, SaaS)을 비교하고, '효과 기반 과금'이나 'AI 에이전트'와 같은 혁신적인 비즈니스 모델이 등장하게 된 배경과 이들이 기존 모델의 한계를 어떻게 극복할 수 있을지 전망하시오.
- 바이트댄스(ByteDance)와 DeepSeek의 AI 전략을 비교 분석하시오. 바이트댄스의 수직 계열화된 생태계 구축 전략과 DeepSeek의 개방형 오픈소스 전략이 각각 어떤 장단점을 가지며, 장기적으로 시장에서 어떤 경쟁 우위를 확보할 수 있을지 논하시오.
- AI 기술의 발전이 가져오는 '내재적 안전 문제'(예: 모델 환각, 알고리즘 편향)와 '응용 안전 문제'(예: 책임 소재, 정서적 윤리)의 상호 연관성을 설명하고, 이러한 복합적인 위험을 관리하기 위해 기술, 법률, 윤리적 측면에서 어떤 다각적인 거버넌스 체계가 필요할지 논하시오.
주요 용어집
| 용어 | 정의 |
| CPI (소비자물가지수) | 주민이 소비하는 상품 및 서비스의 가격 수준 변동 상황을 반영하는 중요한 지표. 최근 중국에서는 하락 추세를 보이며 디플레이션 압력을 나타냄. |
| CNN (합성곱 신경망) | 공간 구조를 가진 데이터(예: 이미지) 처리에 적합한 신경망. 이미지 인식, 객체 탐지 등에 효과적으로 특징을 추출하여 활용됨. |
| RNN (순환 신경망) | 시간적 순서 관계가 있는 데이터 처리에 적합한 신경망. 자연어 처리, 음성 인식, 기계 번역 등 다양한 분야에서 널리 사용됨. |
| GAN (생성적 적대 신경망) | 2014년에 등장한 생성 모델. 판별자와 생성자라는 두 개의 신경망으로 구성되어 이미지, 소리, 텍스트 등 새로운 데이터를 생성하는 데 뛰어난 성능을 보임. |
| Transformer | 2017년 Google이 제안한 자기 주의(self-attention) 메커니즘 기반의 신경망 구조. 대규모 언어 모델의 사전 훈련 알고리즘 아키텍처의 기초를 마련함. |
| Diffusion Model (확산 모델) |
확률적 생성 기반의 딥러닝 모델. 데이터가 정돈된 상태에서 무질서한 상태로, 다시 정돈된 상태로 변하는 과정을 모방하여 노이즈로부터 고품질 데이터를 생성함. |
| SFT (지도 미세 조정) | 특정 작업의 라벨링된 데이터를 이용하여 모델을 미세 조정하여 해당 작업의 패턴을 학습시키는 과정. |
| RL (강화 학습) | 보상 모델의 피드백을 이용하여 모델을 최적화함으로써, 최종적으로 인간의 선호도에 더 부합하는 결과를 생성하도록 하는 학습 방법. |
| RAG (검색 증강 생성) | 외부 지식 베이스를 제공하여 관련 정보를 검색하고, 이를 대규모 모델의 생성 능력과 결합하여 답변의 정확성과 풍부함을 향상시키는 기술. |
| 증류(Distillation) | 잘 훈련된 우수한 대규모 모델("교사")이 특정 응용에 더 적합한 소규모 모델("학생")을 훈련시켜, 적은 계산 자원으로 대규모 모델의 성능에 근접하게 하는 모델 압축 기술. |
| AI Agent | 대규모 모델의 추론 엔진과 도구 체인 생태계를 기반으로, 단순한 대화형 응답을 넘어 자율적으로 의사결정, 실행, 피드백을 수행하는 "디지털 노동력". |
| 물리 AI (Physical AI) | 디지털 지능과 물리적 세계를 융합하는 혁신적인 패러다임. 다중모달 감지 및 구체화된 행동 능력을 갖춘 지능 시스템을 구축하여 AI가 가상 비서에서 물리적 협력 파트너로 진화하도록 함. |
| 다중모달 대형 모델 (MLLM) | 여러 종류의 데이터(텍스트, 이미지, 음성 등)를 동시에 이해하고 처리하는 대규모 모델. 생성 지향(DiT)과 이해 지향(MLLM)으로 나뉘며, 두 기술 경로의 융합이 중요한 발전 방향임. |
| MaaS (Model as a Service) |
플랫폼을 기반으로 AI 능력 및 제품 서비스를 사용량에 따라 제공하는 비즈니스 모델. 주로 B2B 분야에서 사용됨. |
| CoT (사고의 사슬, Chain of Thoughts) |
모델이 복잡한 문제를 해결할 때 내부적인 사고 과정을 단계적으로 활용하도록 하는 기술. 이를 통해 추론 능력을 향상시킴. |
| GRPO (그룹 상대 정책 최적화) |
DeepSeek이 강화 학습 훈련에 사용한 혁신적인 모델 구조 및 훈련 최적화 기술 중 하나. |
| 모델 환각 (Model Hallucination) |
모델이 그럴듯해 보이지만 실제 사실과 부합하지 않는 내용을 생성하는 문제. AI의 내재적 안전 위험 중 하나. |